Exago can aggregate data in memory, but it will attempt to push calculations to the database whenever possible to improve performance. This feature is called Database Aggregation.
Aggregating in memory can be under-performant for large sets of data for two reasons:
- The application must pull every individual detail row from the database
- The calculations are done in the application, not the database
Supported aggregate functions are AggCount(), AggSum(), AggMax(), AggMin(), (AggDistinctCount() and AggAvg() with exceptions, see Cases and Exceptions below).
Default supported databases are Microsoft SQL Server, MySQL, Oracle, PostgreSQL, IBM Informix, IBM DB2, Snowflake, SQLite and Redshift. Support can be added manually for additional data sources if needed.
Enabling Database Aggregation
Set Admin Console > General > Database Settings > Aggregate and Group in Database to True. Database aggregation is enabled by default in v2019.1+.
For full coverage of cases it is also recommended to set Admin Console > General > Database Settings > Convert Formulas to SQL to True, so formula aggregations are pushed to the database as well. If this is disabled, only aggregates on data fields will be supported (please take note of the warnings associated with this feature flag).
In addition, it is highly recommended to set Admin Console > General > Other Settings > Run Aggregate Functions at Record Level by Default to True (this is the default in v2019.2+). This setting will control the default behavior of aggregates at the one side of one-to-many joins. Review Aggregates at the entity level for more information.
Aggregates at the entity level
Report builders can choose how aggregations return data when calculating at the one side of a one-to-many join. You can choose to either aggregate at the Entity (Data Object) level or at the Record level.
When aggregating at the Entity level, the result will aggregate the rows of that entity, without taking into account the fact that the one to many join will create additional rows.
For example, in the following report, Orders - OrderDetails is a one-to-many join. Counting the rows at the entity level of Orders will return the number of rows in the Orders object. Counting the rows at the record level will return the number of rows in the table that results from joining Orders to OrderDetails.

This concept generally does not exist in databases. The database will always return the record-level count. Therefore if Exago is asked to perform an entity level aggregate on the one side of a one-to-many join, it cannot push that calculation to the database because it will be incorrect.
To count at the Entity level, the application checks for changes in the Unique Key Fields of the object on the one- side of the join. Therefore, it is important to sort the report by the one- side's unique key fields, otherwise the result is undefined and may be nonsensical.
Precautions
If the Run Aggregate Functions at Record Level by Default setting is set to False OR if users will override this setting by using the RecordLevel argument of any aggregate functions, then ensure that all One-to-Many joins are correctly identified in the configuration so that Exago will not incorrectly push these calculations to the database.
In the Admin Console, expand Data > Joins, and then double-click on the Join, or select the Join and click the Edit  icon. This will open the Joins tab.
icon. This will open the Joins tab.

In the Relation Type drop-down menu, select One To Many. Then click Apply or Okay to save your changes. Do this for each relevant Join.
NoteThe Data Source Metadata Discovery tool cannot identify whether joins are One-to-Many. By default it sets all joins as One-to-One. If you used this tool to autofill Objects and Joins, you must take these precautions before enabling Database Aggregation.
Cases and Exceptions
Database Aggregation will not work on every report, due either to application or database limitations. If a report is not aggregating in the database, inspect the application log for the following line to determine the reason (must be logging at the DEBUG level):
SQL aggregate requirement failed due to: [reason]
The following report functionality is not compatible with database aggregation:
- Column sort
- Execution cache
- Group min/max filter
- Linked report formula
- Reports containing more than one data source (with exceptions, see the next section)
If the report has a sort, filter, group, or aggregate on a formula or a formula custom column:
- Ensure that Convert Formulas to SQL is set to True
- Ensure that all functions included in the formulas have SQL translations for the associated data source by inspecting the dbconfigs.json file
- Translations can be added for custom functions if desired
In the following cases, the report needs to retrieve detail rows, and thus will not aggregate in the database:
- non-suppressed detail section or a cell reference to a detail section
- detail section with a custom function that has the Suppress Database Aggregation flag set to true
- sort, filter, group, or aggregate on a formula that cannot be converted to SQL because there is no translation for the associated data source
AggAvg()orAggDistinctCount()formula in a group that is not the innermost group (this is a limitation due to how these functions work in databases)
The following functionality is not compatible with database aggregation due to product limitations that we plan to address in the future:
- Interactive filters
- Custom aggregate functions
- Pivoted vertical table
- CrossTabs
- Top N filters
Aggregating on Cross-Source Joins
Reports using two data sources can aggregate in the database before joining in memory. This can be enabled by setting the hidden configuration flag <sqlgenerationlevel> to 2. This can generally be more performant than in-memory aggregation, and especially when the data model contains lookup tables. (Available in v2020.1+).
NoteTechnically speaking, we are able to reverse the order of joins and aggregations in these cases, so that we can aggregate in the database before joining in memory. This is usually more performant than joining before aggregating, because the latter would force us to pull all the rows, then join and aggregate in memory.
This will work for reports that contain two distinct data sources (from the list of supported sources) with cross-source joins.
The following exceptions will cause Exago to fall back to in-memory aggregation:
- report contains more than two data sources or two data sources with no cross-source join
- both of the data sources contain aggregates in the SELECT clause (only one source may perform database aggregation)
- all of the groups on the report are formulas, each containing fields from both sources
- there is an aggregate value on a field from the same source as the innermost group field's source and one of the following:
- there is no direct join from the innermost group entity to the other database
- the innermost group is not on the join column of the direct join from the innermost group entity to the other database
Best Practices when Report Building
While Database Aggregation is designed to work invisibly without requiring any additional user input, it cannot work in all scenarios. Each best practice is designed to work around one of the limitations that will prevent aggregation from occurring in the database. In summary they are:
- Separate visualization detail rows to a Linked Report
- Construct tables in the database, not the application
- Use pre-aggregated tables
- Combine functions that can be aggregated in the database
Separate visualization detail rows to a Linked Report
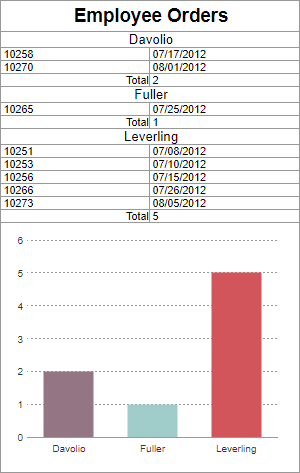
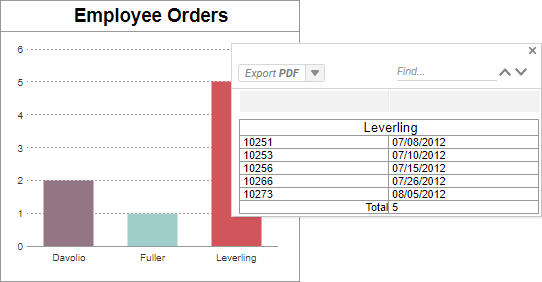
Limitation: Showing detail rows defeats the purpose of database aggregation.
Solution: For visualization reports based on group data, suppress or remove the Detail section. Create a secondary report with the detail rows and link it to the chart as a Linked Report. This way, the primary visualization runs quickly. Then when the database must be queried for detail rows, you will retrieve smaller, filtered subsets instead of the full data set.
Example
Instead of this:
Do this:
Construct tables in the database, not the application
Limitation: Certain types of joins—one-to-many and cross joins (Cartesian products)—and custom columns, which are created in the application rather than the data source, are incompatible with database aggregation.
Solution: Do join and formula logic in the database instead of in the application. As long as a data object generates SQL, then any constructed table will support aggregation in the database. Stored procedures, table-valued functions, user-defined functions, and custom SQL statements are all supported.
Use pre-aggregated tables
Aggregate in the database using custom SQL statements. Using the .NET API's ability to supply custom SQL objects for new reports, create data objects on the fly where the detail rows themselves are simply database-aggregated values for other tables.
Example
The following SQL statement, supplied in a custom SQL object through the API, joins two tables and returns three aggregated columns before ever reaching the Exago application.
SELECT Order.Id AS Id, COUNT(OrderDetail.Id) AS IdCount, MAX(OrderDetail.OrderId) AS OrderMax, MAX(OrderDetail.ProductId) AS ProdMax FROM OrderDetail INNER JOIN Order ON (OrderDetail.OrderId = Order.Id) GROUP BY Order.Id ORDER BY Order.Id ASC
Combine functions that can be aggregated in the database
Limitation: Custom aggregate functions cannot be written to the dbconfigs.json FormulaDictionary, so they cannot be aggregated in the database.
Solution: Instead combine functions that can be aggregated in the database together.
Example: The Custom Aggregate Function: AggCountIf() can instead be made to aggregate in the database by nesting AggSum() and If().
Instead of applying this formula with a single custom aggregate function:
=AggCountIf({Products.ProductName}, {Products.Discontinued})
Use a combination of these functions:
=AggSum(If({Products.Discontinued},1,0))