The Scheduler Queue is a custom-built application library that sits between the Exago core application and any number of Scheduler Service instances and handles how schedule traffic is managed. The Scheduler Queue is completely optional, but configurations with multiple scheduler instances for which load balancing is a priority are ideally suited to making use of this feature.
Background
The way in which Exago has historically handled report scheduling and the default behavior without using a queue, is the following.
For this discussion, it's important to define some terms:
- A Schedule represents all of the information that a Scheduler Service needs to execute a report. A Schedule contains information such as report name, time and frequency of execution, and how to handle the result. This information is usually stored as an XML file in a repository. Schedules can be accessed from the .NET API using the ReportScheduler class.
- Each Schedule contains some interpreted data that tells a Scheduler Service when to run it. This information is called a Job. Jobs can also be stored separately from Schedules. Jobs can be accessed from the .NET API using the QueueApiJob class.
- The process whereby a Scheduler Service runs a report at a specified time and emails or saves the information is called an Execution.
Within the host application, all Scheduler Service instances are listed in the configuration XML file:
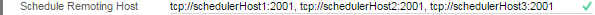
When a Schedule is created in the Web Application, the host application sends the job to Scheduler Services starting with the first and moving through the list ("round-robin" style). The queried Scheduler Service stores the Schedule XML in a local working directory. This acts as a repository for the Scheduler Service's unique set of jobs.
From this point, each Scheduler Service works independently. The host application has no idea what happens to schedules after they are sent out successfully. Likewise, the Scheduler Services have no more communication with the host application with regard to report execution.
NoteSchedules can be viewed and edited from the Web Application using the
Schedule Manager, but this is essentially a combined front-end for the Scheduler Service's existing files. If a Scheduler Service is offline, its schedules do not appear in the list (there will be a warning message). The Schedule Manager has no impact on the host application.
Scheduler Services periodically scan their repository for job execute times. If a job is ready and the current time is equal to or past the execute time, the Scheduler Service knows to run the job. The Scheduler Service will perform its duty and then alter the schedule XML file to indicate success or failure and the next execute time.
This default behavior may be adequate for most cases, but there can be issues. In particular, the Scheduler Queue sets out to solve the following two issues that can arise in default configurations: Load Balancing and Unexpected Outages.
Load Balancing
Ideally, unoccupied Scheduler Services would receive new jobs. This way, stacks of unexecuted data do not build up on individual Scheduler Services, leading to unbalanced load and potential time loss. But the host application has no idea which schedulers will be busy when, and no idea how long jobs will take to run. The randomness of round-robin job assignment could cause jobs to build up inordinately on one Scheduler Service.
Outages
Once the host application sends out a schedule, as far as it's concerned, it's finished. If a Scheduler Service goes offline unexpectedly the host has no recovery function. The job will simply be delayed until the Scheduler Service is restarted. There is also no function to move schedules from one Scheduler Service to another.
How the Queue Works
The Scheduler Queue is a custom .NET or Web Service library which aims to handle scheduling in a more robust manner. It's important to note that the queue is entirely customizable. You are only required to implement the applicable methods; how you do so is up to you. The following section will describe a typical setup which can improve load balancing and help resolve some common issues with multiple Scheduler Services.
The queue sits in between the Exago host application and any number of Scheduler Services and handles logic for all scheduler requests and maintenance.
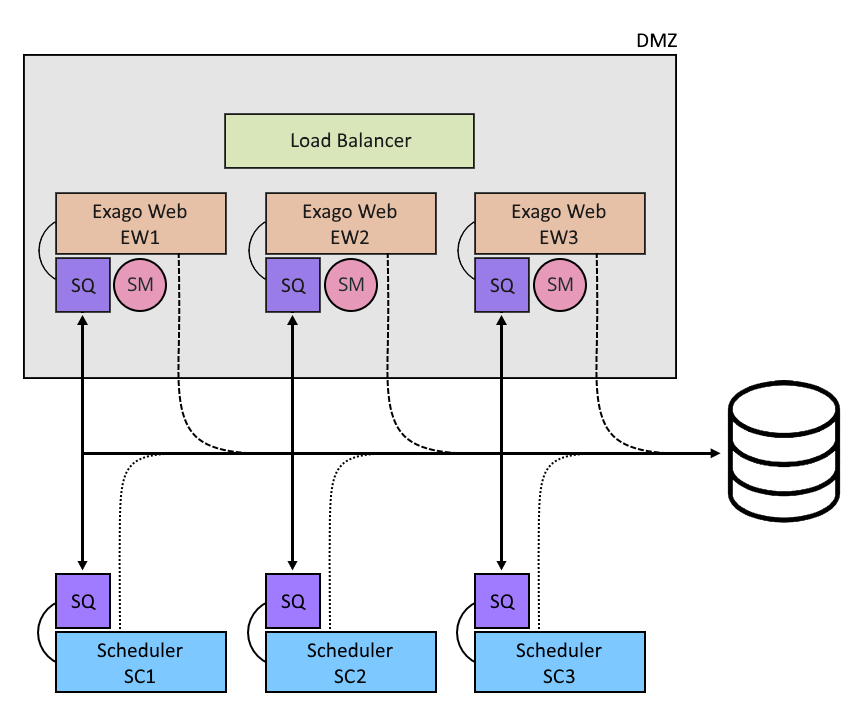
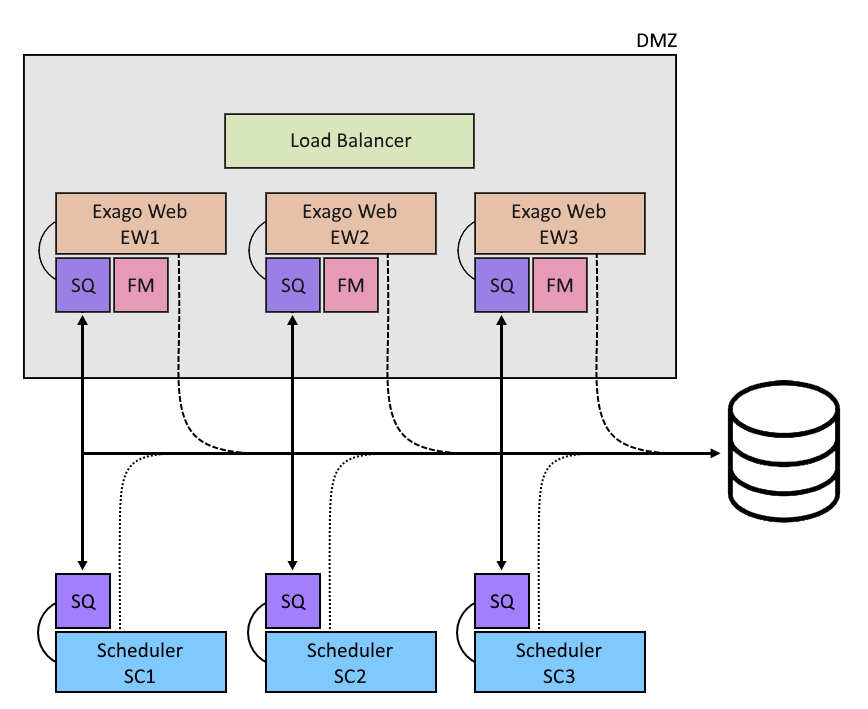
The host applications and Scheduler Services all make calls to the queue at certain points during their runtime. In particular, Scheduler Services will call the queue on three occasions: upon service startup, periodically while running, and when a job's status is changed. The host application calls the queue for various maintenance tasks related to schedule creation and populating the Schedule Manager. For now, we'll focus on the relationship of Scheduler Services to the Scheduler Queue and how it can aid a typical multi-scheduler configuration.
When Scheduler Services are configured to use the queue, their behavior changes somewhat.
NoteIn the default configuration, Scheduler Services store their unique schedules in a local working directory, from which jobs are queried for execution.
Scheduler Services now periodically query the queue, which has instructions (GetNextExecuteJob) for assigning jobs. (The query time defaults to 15 seconds, but is configurable). In a typical setup, the queue pulls from a central repository of stored schedules. In order to prevent duplication, Scheduler Services lock the queue so that only one may access it at a time. Additionally the Scheduler Queue sets a job's status to "running" while it's active, so that other Scheduler Services know to ignore it.
NoteScheduler Services still use a local working directory for temporary files.
This has several advantages. First, Scheduler Services are no longer responsible for a unique set of schedules. This prevents outages from causing excessive missed executes. Only one job will ever be hung per Scheduler Service as it will be responsible for only one job at a time. If a Scheduler Service goes offline in the middle of a job, the Scheduler Queue can be used to gracefully handle incomplete jobs.
Next, jobs are now distributed much more evenly between the Scheduler Services. Jobs will only be assigned to available Scheduler Services. Finally, since this allows us to control what data is being sent and received to the Scheduler Services and the file system, any custom load balancing solution can be implemented.
Set Up
Setting up the Scheduler Queue is a multi-part process which depends on the desired configuration. We'll discuss some constants and some potential variations.
Write the Scheduler Queue
First we need to write the Scheduler Queue. This can be a .NET Assembly or a Web Service, and it can be part of another library.
All the following methods must be implemented in the Scheduler Queue interface:
public static string[] GetJobList(string viewLevel, string companyId, string userId)
Called from the Exago Web Application to populate the jobs in the Schedule Manager.
public static string GetJobData(string jobId)
Called from the Exago Web Application Schedule Manager to get the full job XML data.
public static void DeleteReport(string reportId)
Called from the Exago Web Application when a report is deleted.
public static void RenameReport(string reportId, string reportName)
Called from the Exago Web Application when a report is renamed.
public static void UpdateReport(string reportId, string reportXml)
Called from the Exago Web Application when a report is updated.
public static void Flush(string viewLevel, string companyId, string userId)
Called from the Exago Web Application Schedule Manager in response to a click on the  Flush icon.
Flush icon.
public static void Start(string serviceName)
Called from Scheduler Services to indicate when a specific service starts.
public static string GetNextExecuteJob(string serviceName)
Called from the Scheduler Services to return the next job to execute.
public static void SaveJob(string jobXml)
Called from both the Scheduler Service and the Exago Web Application to save the job. This method is called when a schedule is added, updated, completed, killed, etc.
The QueueApi and QueueApiJob helper classes have been added to the API to facilitate writing the Scheduler Queue. You'll need to reference the WebReports.Api.Scheduler namespace. QueueApiJob wraps a Job object and a variety of useful methods for managing jobs. The QueueApiJob class will be used extensively in the following example.
Configuration
The host application config and each Scheduler Service config must contain the path to the Scheduler Queue assembly or Web Service class in the following format:
Assembly=Path\To\Assembly.dll;class=Namespace.Class
The path may be set by one of these methods:
- Using the Admin Console by setting the General > Scheduler Settings > Custom Queue Service field.
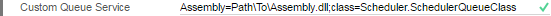
Setting the Custom Queue Service field in the Admin Console - By setting the field <schedulerqueueservice> in the config file,
- By setting the field Api.SetupData.General.SchedulerQueueService via the .NET API at runtime.
In each Scheduler Service, set the field <queue_service> in the config file.
Next, determine how schedules are accessed. A common solution uses a database to optimize lookup speed. The queue only needs to know the Job ID (filename), Next Execute Time, and the Running status to determine which schedules to run.
|
Job ID |
Next Execute Time |
Running? |
|
String |
DateTime |
Boolean |