Use the Categories window to select which data to use on the report. The left pane shows the data categories you can access. To see the fields in a category, select it and click the View Category Fields  icon.
icon.
If the report has a custom SQL category then it cannot have any other categories. You can click the SQL  icon to edit the SQL statement. See SQL Categories for more information.
icon to edit the SQL statement. See SQL Categories for more information.
What are Data Categories?
Data Categories are tables of data, which are organized by rows and columns. Columns are also known as data fields. A row of data has entries for one or more columns in the category. When you add a data field onto a report you are seeing the information in one column of data for every row in the category.
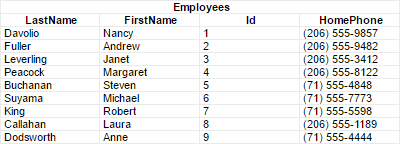
For example, a data category for Employees could have columns for the first and last names of each employee, an identification number, and a home phone number. Each row represents a person, and each column contains a specific type of information such as last name or phone number.
You add entire categories at a time to a report, but in the report view you select only the columns you want to see. When you add a data field to the report design, even though you only see one column, the rest of the table is still present behind the scenes. You will never lose the connections between items in each row, and you can always add more fields.
Relationships Between Categories
NoteThis information is intended for advanced users.
In the data source, data categories are joined to other categories by associating uniquely identifying data fields from one category to matching data fields in another. This means that if a row's identifying field matches one or more rows in a joined category, then those rows connect to an entire row or group of rows, which have their own separate data fields.
Only joined data categories, which are described as having a relation, can be added to the same report. This is why some categories may become unavailable as you add others. But data categories, even if they are not related to each other, may both be related to another category. If you add that category, then you can add both those categories, because there is now a join path between them.
For more information on how categories are related to each other, see Joins.
Suppressing Duplicates
NoteThis information is intended for advanced users.
Be judicious when adding data categories. If you find that your report has unexpected duplicate values or empty rows, the cause is most likely that you have a one-to-many join to a category that you are not using.
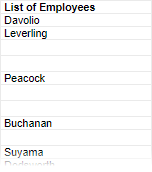
For example, this report has Employees and Orders categories. There is a one-to-many join from Employees to Orders, indicating that each Employee row is joined to one or more Order rows. Even though we are not using Orders on the report design, there are duplicate Employees because our join setup causes us to have a row for each Order, instead of each Employee.
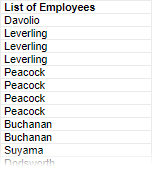
There are several ways to eliminate these duplicates. You can suppress duplicates for the Employees category, which will show blank rows for consecutive duplicates. In the Categories window, select the Suppress Duplicates check box for the Employees category.
You can also suppress duplicates for the cell, which will hide unnecessary duplicate rows. Select the cell and click the Suppress Duplicates  icon. If a field from Orders is on the report, the behavior will be the same as suppressing duplicates for the category.
icon. If a field from Orders is on the report, the behavior will be the same as suppressing duplicates for the category.
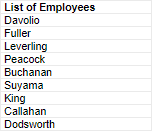
Or, if you do not think you will need the Orders category, remove it from the report. In the Categories window, click the Delete Category  icon next to Orders to remove the category. You can always add it again later if needed.
icon next to Orders to remove the category. You can always add it again later if needed.