Grouping a column of data breaks up the rows into sections which share a common trait. Each iteration of a group is a unique row in a data column. Grouping data allows you to easily identify rows with common factors. You can perform calculations on groups, such as counting the rows, or adding up the data in each iteration.
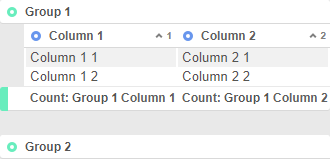
Grouping data in an ExpressView
Making a group
To create a group from a column, use  radial>up or right-click the column and select Group in the dropdown menu. This turns the data column into a group column, and organizes the other columns by each unique row in the group. Each row in the data column becomes a group section, or iteration, and the rows in other columns are grouped by the section which they are related. The group is also given a new color to distinguish it from the data rows. Remember to turn Live Data on to see your actual data and verify that this is the grouping you want.
radial>up or right-click the column and select Group in the dropdown menu. This turns the data column into a group column, and organizes the other columns by each unique row in the group. Each row in the data column becomes a group section, or iteration, and the rows in other columns are grouped by the section which they are related. The group is also given a new color to distinguish it from the data rows. Remember to turn Live Data on to see your actual data and verify that this is the grouping you want.
To ungroup a column, use radial>left or right-click and select Ungroup from the dropdown menu. This turns the group column back into a data column.
Groups can be created inside other groups. These are called nested groups. To make a nested group, simply add another group to an ExpressView which already has one. This creates another grouping inside the existing group. Additional levels of nesting can be made as needed.
Note: Right-click interactions added in v2018.2.
Changing group level
If you have two or more levels of grouping, you may decide that they are nested improperly. For example, if you had Products grouped by Orders, then you add another grouping on Employees, you may end up with Products grouped by Employees grouped by Orders.
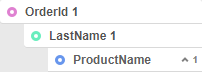
Improper grouping of data fields
However, it makes more sense to have Orders grouped by Employees instead, since Employees have multiple Orders, but Orders does not have multiple Employees. To move the Employees group up one level, use radial>up on the group column or right-click the group header and select Move Group Up One Level.

Proper grouping of data fields
Dropdown menu
Summarizing group data
Each iteration has a footer, which contains summary calculations, also known as aggregates, for each column. The ExpressView also has a report footer, which calculates the aggregate across all the groups. You can choose between several options for which calculation you want to appear in the footer for each column.
To change the calculation for a column, click a footer and select one of the following options:
Sum
Totals the data values in the iteration. Only available for numeric fields.
Min
Shows the smallest data value, or first value alphabetically, or earliest date in the iteration.
Max
Shows the largest data value, or last value alphabetically, or latest date in the iteration.
Count
Counts the number of values in the iteration.
Distinct Count
Counts the number of distinct values in the iteration.
Avg
Takes the average, or arithmetic mean, of the values in the iteration. Only available for numeric fields.
None (v2017.3+)
Show no summary calculation.
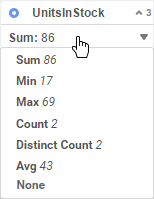
Choosing an aggregate
For more information on aggregation, see this article.
Hiding data rows
If you only want to see the summary calculations, you can hide the data rows, either per-iteration, or for every group in the ExpressView. This does not remove the data or alter the summaries. It only hides the rows from view.
To hide the rows for one iteration or several iterations, click the group header for each iteration to toggle whether its rows are shown or hidden.
To hide or show all the rows in the ExpressView:
- Click the Display
 icon in the toolbar.
icon in the toolbar. - Click Hide All Group Content to hide all the rows, or Show All Group Content to show all the rows.
- To remove all data rows from the report and only show summary data, deselect Include Detail Rows. This may improve the performance for reports that do not depend on the detail values.
If you have nested groups, this hides all but the top level groups.